Introduction to LLM Transformers
Large Language Models (LLMs) have become a cornerstone of artificial intelligence (ai) development, revolutionizing the way we process and understand language. In this post by Moodbit, we explore the inner workings of LLM transformers—delving into both the historical evolution and the technical details that make these systems remarkably powerful. Our discussion not only highlights the key components like multi-head attention, encoder-decoder architectures, and transfer learning, but also connects these concepts with practical applications in modern digital ecosystems, including integrations with google drive and onedrive. Prepare to journey from broad overviews into the intricate details that power the next generation of ai-driven insights and summaries.
Transformer Foundations and the Birth of Attention
At the heart of LLM transformers is an innovative architecture that shuns traditional recurrence and convolutions in favor of an attention mechanism. The foundational paper, “Attention Is All You Need,” published in June 2017, introduced the concept that would soon change the landscape of natural language processing. This breakthrough illustrated how transformers can process entire sequences of text simultaneously. The model is divided into two key segments: the encoder, which processes input sentences by converting tokens into embeddings—enhanced with positional encodings to preserve word order—and the decoder, which uses these context-rich representations to generate output token by token. This unique structure enables deep contextual understanding and rapid, dynamic text generation.
The Encoder-Decoder Architecture Explained
The encoder-decoder framework is central to the functioning of transformer models. The encoder receives input text, tokenizes it, and converts it into high-dimensional numerical representations that capture the inherent meaning and context of the language. Each encoder layer comprises a self-attention sublayer and a feed-forward network. These layers work in unison with residual connections and layer normalization to maintain stability and performance during training. The result is a refined set of features that embody the nuances of the input.
Conversely, the decoder is responsible for generating outputs such as translations, summaries, or any other task requiring text generation. It operates in an autoregressive manner, meaning each generated token is influenced by its preceding tokens. The decoder employs three sublayers: the causally masked self-attention layer which prevents the model from “peeking” at future tokens, a cross-attention layer which integrates the encoder’s context, and a feed-forward network that further refines the output. This combination allows the model to provide accurate and contextually appropriate responses.
Multi-Head Attention Mechanism
A critical component that differentiates transformers from prior models is the multi-head attention mechanism. Instead of focusing on a single perspective, the multi-head approach divides the embedding space into several subspaces (or heads), allowing the model to capture diverse aspects of language simultaneously. For instance, an embedding of size 512 might be split into 8 heads, each of dimension 64. Every head independently computes Queries (Q), Keys (K), and Values (V) through learned linear projections.
The process involves computing attention scores by taking the dot product between the Query vector of one token and the Key vectors of all other tokens. These scores are scaled by the square root of the key’s dimension and passed through a softmax function to create a probability distribution. The resulting weights are then used to calculate a weighted sum of the Value vectors, effectively creating contextualized token representations. Once all heads have processed the input, their outputs are concatenated and passed through a final linear layer to blend the diverse attention signals. This mechanism not only enhances the model’s interpretability by enabling different heads to focus on varying aspects like syntax and semantics, but it also boosts overall performance on complex NLP tasks.
Historical Milestones and Evolution
Transformers have undergone significant evolution since their inception. Notable models include:
- GPT (June 2018): Initiated the era of pretrained transformer models and demonstrated the potential of fine-tuning on different tasks.
- BERT (October 2018): Introduced an auto-encoding strategy focused on understanding and summarizing text, establishing benchmarks in language comprehension.
- GPT-2 (February 2019): An enlarged version of its predecessor with superior performance in generating fluent and context-aware text.
- DistilBERT (October 2019): A trimmed, efficient variant of BERT designed for faster inference while maintaining robust performance.
- BART and T5 (October 2019): Models emphasizing the sequence-to-sequence methodology, ideal for translation and text summarization tasks.
- GPT-3 (May 2020): Demonstrated the power of scale with zero-shot learning capabilities, effectively performing tasks without fine-tuning.
These milestones not only highlight the progression from earlier models to more complex systems but also underscore the importance of transfer learning. Models are first pretrained on vast amounts of raw text using self-supervised learning methods—capturing statistical representations of language—and are then refined for specific applications through supervised fine-tuning. This two-step approach significantly reduces the need for extensive task-specific data while optimizing compute resources and minimizing environmental impact.
Diving Deeper: Self-Attention and Its Impact
Self-attention is arguably the backbone of transformer architectures. It enables each token in an input sequence to interact with every other token, ensuring that contextual relationships are maintained regardless of the tokens’ positions. This is where the magic of multi-head attention comes into play, allowing the system to simultaneously learn multiple forms of word interactions. The self-attention mechanism provides a fine-grained analysis of the text, leading to more accurate and insightful modifications, whether it’s in translating languages, generating summaries, or performing sentiment analysis.
For those seeking more detailed technical insights, trusted resources such as the research articles published on Attention Is All You Need and introductions to GPT models offer concrete explanations and further reading. These resources complement the technical narrative by providing code snippets, mathematical derivations, and visual diagrams that depict how self-attention and multi-head mechanisms function.
Visualizing the Transformer Architecture
Understanding complex systems is greatly enhanced by visual aids. Typical diagrams of the encoder-decoder architecture illustrate both the broad structure and the intricate details of transformer modules. One can imagine an image where the encoder is displayed on the left (or bottom) and the decoder on the right (or top), with arrows representing the flow of information between modules. The encoder’s block is often depicted as multiple layers performing self-attention and feed-forward processing, whereas the decoder showcases a more nuanced structure, incorporating masked self-attention, cross-attention, and additional feed-forward networks.
Here is an illustrative image description designed to complement your learning experience: 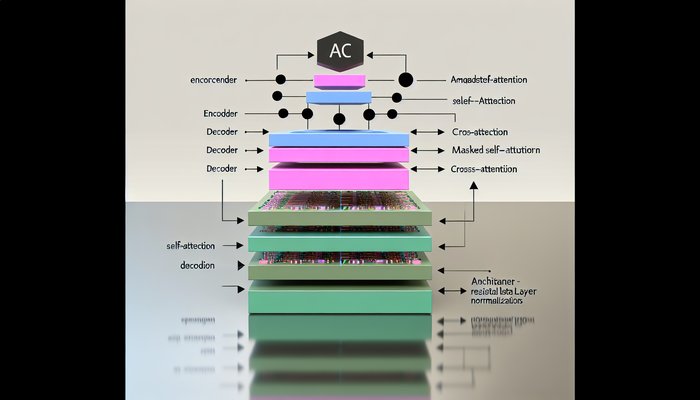 This diagram serves as an invaluable resource to visualize how transformers process and generate language, thereby bridging the gap between abstract theory and practical insight.
This diagram serves as an invaluable resource to visualize how transformers process and generate language, thereby bridging the gap between abstract theory and practical insight.
Integrating with Modern Digital Workspaces
Beyond the theoretical and technical aspects, the capabilities of LLM transformers are being harnessed in diverse digital environments. Companies are increasingly leveraging these models to drive automated insights and summaries across various platforms. For instance, integrations with platforms like google drive and onedrive are streamlining data management and boosting workflow efficiency. With tools like DataChat by Moodbit, users can seamlessly interact with their data repositories directly from their chat applications, thereby reducing the friction of switching between multiple applications.
Such integrations empower businesses to unlock hidden analytics and actionable insights in real-time. This enriches decision-making processes and fosters a proactive culture of data-driven strategies. By coupling advanced LLM transformers with intuitive user interfaces, digital assistants transform how users retrieve information, generate reports, and contemporaneously access valuable summaries from diverse data sources.
Practical Applications and User Benefits
The diverse architectures of Transformer models have led to a myriad of practical applications. Organizations now harness these models for tasks such as:
- Text Generation: Creating coherent and context-aware content or generating creative narratives.
- Machine Translation: Translating languages by effectively mapping source and target language structures via cross-attention mechanisms.
- Summarization: Condensing lengthy documents and extracting key insights for quick consumption—an essential feature in managing the vast amount of content stored in platforms like google drive and onedrive.
- Sentiment Analysis: Assessing text inputs to determine emotional tone and underlying sentiment, a critical tool for market research and customer feedback.
This seamless blend of connectivity between advanced LLM transformers and user-friendly applications exemplifies how technology can transform everyday tasks into highly efficient processes. Whether you are an academic, a business professional, or simply an ai enthusiast, the potential of these systems to generate robust insights is limitless.
Conclusion and Call to Action
In summary, the inner workings of LLM transformers—spanning transformer foundations, multi-head attention mechanisms, and encoder-decoder architectures—represent a monumental leap in our approach to natural language processing. The intricate design of these models allows them to capture subtle linguistic patterns, process vast amounts of data, and generate human-like text with unparalleled efficiency. As you explore further, don’t hesitate to visit additional resources like the detailed breakdowns available in the Hugging Face NLP course or review the seminal research papers linked throughout this post for deeper insights. Embrace the future with Moodbit’s cutting-edge technologies and let these innovations drive your next steps in understanding and leveraging ai. Start your journey today to unlock the full potential of your data and transform your workflow with advanced LLM transformers, enriched insights, and comprehensive summaries.
Leave a Reply